JS Series: Using Atomics to Handle Concurrent Writes from Workers
Author
Elle J
Date
May. 20, 2024
Time to Read
30 min
Prerequisites
- ★Any programming language (intermediate knowledge)
- ★Curiosity
Motivated by enabling more powerful parallelism to JavaScript, the team at Mozilla working on Firefox's JavaScript engine (SpiderMonkey) had previously started experimenting with APIs for shared memory. The features in the proposal for "Shared Memory and Atomics", such as the shared memory type SharedArrayBuffer, were ultimately added to the language as part of ES2017.
With parallelism and allowing threads to access the same memory, various complicated concurrency problems also get introduced. Therefore, a global Atomics object with static methods for dealing with parallelism and concurrency was also included in the ECMAScript proposal.
This article will introduce those features and the relevant related concepts, as well as implement examples of how to handle concurrent writes by using Atomics. Specifically, I'll cover these areas:
- How to create background threads using Web Workers.
- How to communicate between threads.
- APIs used:
postMessage(),onmessage
- APIs used:
- How to transfer the ownership of an object's associated memory.
- Understanding when
SharedArrayBufferis useful. - What
Atomicsand atomic operations are. - How to implement a shared counter.
- APIs used:
Atomics.add(),Atomics.sub(),Atomics.load()
- APIs used:
- How to implement a mutex.
- APIs used:
Atomics.compareExchange(),Atomics.wait(),Atomics.notify()
- APIs used:
- How to implement atomic-looking operations using a mutex.
- How to implement a shared counter using our custom mutex.
This article will also explain some of the JavaScript internals of the APIs used to give you an extra knowledge boost 💪.
With that, let's dive right in.
(The implemented examples can also be found in my GitHub repository.)
Table of Contents
- Using Web Workers to Run Tasks in Parallel
- Transferring Ownership and Shared Buffers Between Threads
- Problems with Shared Memory
- Introducing Atomics
- Implementing a Counter Using Atomic Operations
- Updating the Counter in Background Threads
- Triggering Concurrent Writes via UI Interactions
- Implementing a Mutex to Create Atomic Operations
- Thank You for Reading
Using Web Workers to Run Tasks in Parallel
Performing computationally intensive operations on the main thread (e.g. the UI thread) could potentially slow down a web application significantly by blocking execution of other code such as updates to the DOM. In this case, offloading such tasks to one or more background threads allows the main execution to continue in parallel and uninterrupted.
Instantiating a new Worker("some-script.js") is how we can create a new background thread to have the web worker object execute some-script.js. By design, workers are isolated and thus use a messaging system to communicate with their creator (the main thread in this case) and vice versa. Essentially, all actors (main and workers) can send messages to a specific actor (by calling postMessage()) and listen for messages sent to them (by setting onmessage or calling addEventListener("message", ..)).
The below example shows a worker script that will log the message sent from the main thread and then send a message back to it.
// say-hi-worker.js
function handleMessageFromMain({ data }) {
console.log(data);
postMessage(`Hi from ${self.name}!`);
}
onmessage = handleMessageFromMain;postMessage and onmessage are available on the global scope, which for dedicated worker contexts is the DedicatedWorkerGlobalScope (also accessible via self). Thus, there is no access to window here. The event received contains a data property with the message emitted, which can be almost any JS object or value (we will revisit the limitations later on).
On the main thread, let's initialize four workers, attach a listener to each one that will log messages sent from the worker once received, then emit a message to each worker.
// main.js
const NUM_WORKERS = 4;
const workers = initWorkers(NUM_WORKERS);
sendMessageToWorkers();
console.log("Messages sent to workers.");
function handleMessageFromWorker({ data }) {
console.log(data);
}
function initWorkers(size) {
const workers = [];
for (let i = 0; i < size; i++) {
const worker = new Worker("say-hi-worker.js", {
name: `Worker #${i}`,
});
worker.onmessage = handleMessageFromWorker;
workers.push(worker);
}
return workers;
}
function sendMessageToWorkers() {
for (const worker of workers) {
worker.postMessage("Hi from the main thread!");
}
}What do you think will be logged to the console? Well, since the workers execute in parallel, one may finish earlier than the other, so the time at which the worker posts the message depends on the amount of work it is doing prior to that. In this example however, each worker only logs the data, creating the following output most of the times:
Output:
Messages sent to workers.
Hi from the main thread!
Hi from Worker #0
Hi from the main thread!
Hi from Worker #1
Hi from the main thread!
Hi from Worker #2
Hi from the main thread!
Hi from Worker #3Do note that even though sendMessageToWorkers() was invoked before console.log("Messages sent to workers."), the latter was not blocked by the operations performed by the workers.
Transferring Ownership and Shared Buffers Between Threads
Even though communication between the threads are enabled by posting messages, this can become quite costly as the data is copied every time. When an object is sent, it will first be serialized, then deserialized on the receiving end, creating a new (not shared) instance.
If threads need to access the same resource, one way of reducing the copying cost is to transfer the object and the ownership of the associated memory. Such objects are referred to as transferable objects. Depending on the object being transferred, this can sometimes be done in a zero-copy operation.
// main.js
const uInt8Array = new Uint8Array(Uint8Array.BYTES_PER_ELEMENT);
console.log(uInt8Array.byteLength); // 1
const worker = new Worker("some-script.js");
// Transfer the underlying `ArrayBuffer` since `TypedArray`s
// such as `Uint8Array` are not transferable objects.
worker.postMessage(uInt8Array, { transfer: [uInt8Array.buffer] });
// same as: worker.postMessage(uInt8Array, [uInt8Array.buffer]);
console.log(uInt8Array.byteLength); // 0However, transfering the ownership only allows for one thread at a time to access the object, as doing so to the original object will throw an exception. This is when the shared memory type SharedArrayBuffer becomes useful.
By sharing (not transferring) a SharedArrayBuffer with other threads, all agents involved can reference the chunk of memory it represents at the same time. We'll look at this shortly.
Curiosity Checkpoint 🤔
What do you think will happen (or should happen) if two agents write to the same memory location at the same time? And can the behavior be predicted? When working with shared memory, several interesting and unpredictable scenarios can happen if there is no synchronization or coordination between the operations. Let's look at two scenarios before demonstrating how Atomics can help us address exactly that.
Problems with Shared Memory
Imagine that we have two threads with access to the same resource (sharedMemory). Thread 1 is deliberately waiting for Thread 2 to signal when it is okay to proceed execution, by continuously checking if the data at location has been updated.
// Thread 1
while (sharedMemory[location] === 1) {
/* keep looping until Thread 2 updates the data.. */
}
console.log("The wait is over!");
// Thread 2
// At some point, Thread 2 will update the data:
sharedMemory[location] = 0;The problem is, we might never see the output The wait is over!. Since the two threads are not synchronized (reading from sharedMemory is not synchronized with writing to it), some compilers will perform optimization on the read, even for shared memory, like so:
// Thread 1
let data = sharedMemory[location];
while (data === 1) {
/* keep looping forever.. */
}
console.log("The wait is over!");So unless data is not 1 by the first read, we will be stuck in an infinite loop.
Another issue with non-synchronized code between threads arises from concurrent reads and writes, namely data races. Suppose we have a shared counter starting at value 0 and increment it by 1.
counter += 1;At a high level, the above operation may look like it is performed as one indivisible (atomic) step, and other such concurrent operations appear sequentially consistent. But an operation like incrementing a value in memory oftentimes involves more steps, such as loading the value from memory, adding 1 to the loaded value, then storing it back into memory:
value = sharedMemory[counterAddr]
value = value + 1
sharedMemory[counterAddr] = valueThus, it is possible for another thread to read or write to the same address in the middle of executing the first increment:
// Thread 1 // Thread 2
Step 1: value = sharedMemory[counterAddr]
Step 2: value = value + 1 value = sharedMemory[counterAddr]
Step 3: sharedMemory[counterAddr] = value value = value + 1
Step 4: sharedMemory[counterAddr] = valueTo appear sequentially consistent, two threads that each increment the counter by 1 should result in 2 being stored in memory. From the above example, Thread 2 reads the value 0 from memory at Step 2, then increments it, then stores the value 1 in memory, overwriting the previously stored value by Thread 1.
Due to the possibilities of data races when working with shared memory, there are guidelines provided in the Memory Model of the ECMAScript specification. This finally brings us to Atomics.
Introducing Atomics
The global Atomics object exposes static methods for performing operations on shared memory atomically, such as Atomics.add() and Atomics.load(). In the previous example where two threads increment a counter concurrently, replacing the high-level code counter += 1 with using Atomics.add() as we'll do momentarily, would make the operations execute one after the other. The previous example with Thread 1 and Thread 2 would then look more like the following:
// Thread 1 // Thread 2
Step 1: value = sharedMemory[counterAddr]
value = value + 1
sharedMemory[counterAddr] = value
Step 2: value = sharedMemory[counterAddr]
value = value + 1
sharedMemory[counterAddr] = valueUsing such APIs introduces synchronization that signals to compilers to not perform certain optimizations that could otherwise break the expectation of atomicity. (Interestingly nonetheless, atomics do get optimized by, for instance, making operations either more or less atomic as long as the program remains sequentially consistent.)
When, for instance, Atomics.add() is invoked, a so-called Shared Data Block event is introduced (specifically a ReadModifyWriteSharedMemory event) specifying that the order of the operation should be sequentially consistent.
To try this out in the browser and see it in action, we will implement the following:
- A counter
- Stores the value (the count) in the underlying
SharedArrayBuffer. - Provides public methods for incrementing, decrementing, and reading the value.
- Stores the value (the count) in the underlying
- A worker script
- Updates the counter by calling the above public methods.
- Which operation is performed depends on the message sent by the main thread (controlled by user interaction).
- Each worker either increments or decrements the counter 100,000 times by 1.
- Once done counting, it tells the main thread that it is done and sends along the new count.
- A main script
- Initializes four workers with the above worker script.
- Sets up DOM event listeners that, when notified, will have the main thread tell the workers which operation to perform.
- Once it receives a message from a worker being done counting, it updates the DOM with the new value.
Other files such as index.html can be found in the demo repository for this blog post. Important to note is that SharedArrayBuffer is only supported if the pages served are cross-origin isolated (a restriction originating from a security vulnerability making it possible for code to read otherwise inaccessible memory). The repository therefore also contains server.js which is a minimal HTTP server using Bun (see the README for a one-step instruction on how to start it).
Implementing a Counter Using Atomic Operations
First, let's create a Counter class in a new file counter-example2.js. (counter-example1.js in the demo repository shows an implementation of a non-synchronized counter, and how it produces unpredictable results.)
Its constructor expects the buffer representing the shared memory. A buffer is merely a chunk of data containing the raw binary values. Since it does not store any information on the format of the data, such as the type, it needs to be wrapped in a so-called view, or typed array view. Views provide a way of accessing the data in the buffer via bracket notation like normal arrays. Although, keep in mind that they are not Arrays; instead, typed arrays such as Uint32Array, Int8Array, etc. all have TypedArray (which is not globally available) as their superclass.
// counter-example2.js
/**
* A counter which updates the value in shared memory using `Atomics`.
* This allows for concurrent writes to appear sequentially consistent,
* producing a predictable counter.
*/
export class Counter {
/**
* The location in the `bufferView` at which the value is stored.
*/
static #LOCATION = 0;
/**
* The view into the underlying buffer by which it is accessed.
*/
#bufferView;
/**
* Create a counter backed by shared memory.
*
* @param {SharedArrayBuffer} sharedBuffer - The shared data buffer.
*/
constructor(sharedBuffer) {
this.#ensureSharedArrayBuffer(sharedBuffer);
this.#bufferView = new Uint32Array(sharedBuffer);
}
/**
* @param {unknown} value
*/
#ensureSharedArrayBuffer(value) {
if (!(value instanceof SharedArrayBuffer)) {
throw new Error("Expected a 'SharedArrayBuffer'.");
}
const MIN_BYTES = Uint32Array.BYTES_PER_ELEMENT;
if (value.byteLength < MIN_BYTES) {
throw new Error(`Expected at least a ${MIN_BYTES}-byte buffer.`);
}
}
}As the counter will store one Uint32 value (the current count), we will always access the view at location, or index, 0 in this example. An alternative approach is to have the constructor accept it as an argument. That would allow for callers to pass the same buffer around where other shared buffers are expected, but use different offsets into the memory.
Now, let's implement our atomic operations.
// counter-example2.js (continuing)
export class Counter {
// ...
/**
* @returns {number} The current count.
*/
get value() {
return Atomics.load(this.#bufferView, Counter.#LOCATION);
}
/**
* Increment the counter.
*
* @param {number} value - The value to increment by.
*/
increment(value = 1) {
Atomics.add(this.#bufferView, Counter.#LOCATION, value);
}
/**
* Decrement the counter.
*
* @param {number} value - The value to decrement by.
*/
decrement(value = 1) {
Atomics.sub(this.#bufferView, Counter.#LOCATION, value);
// NOTE: This is not accounting for decrementing below
// 0, which will overflow due to storing Uint32.
}
}These are quite straightforward APIs. One thing not demonstrated here, however, is that both Atomics.add() and Atomics.sub() return the old value at the given location.
Since we will experiment with different counter implementations, let's go ahead and create a counter.js file for importing the various examples and exporting just one Counter. Other files can then import { Counter } from "./counter.js" without worrying about updating these imports when trying another example.
// counter.js
// import { Counter } from "./counter-example1.js";
import { Counter } from "./counter-example2.js";
export { Counter };Updating the Counter in Background Threads
Before setting up the main script that will send messages to the workers to say which operation to perform, we will implement the worker script counting-worker.js.
Apart from the operation, the workers also expect the main thread to send the sharedCounterBuffer, with which it will instantiate a new counter. It then invokes either the increment() or decrement() method 100,000 times, and sends a message back to the main thread via the global postMessage() method introduced earlier.
// counting-worker.js
import { Counter } from "./counter.js";
/**
* @typedef EventData
* @type {object}
* @property {"increment"|"decrement"} operation
* @property {SharedArrayBuffer} sharedCounterBuffer
*/
/**
* Handle incoming messages from the main thread and either
* increment or decrement the count 100,000 times by 1.
*
* @param {MessageEvent<EventData>} event
*/
function handleMessageFromMain({ data }) {
const counter = new Counter(data.sharedCounterBuffer);
let numUpdates = 100_000;
switch (data.operation) {
case "increment":
while (numUpdates-- > 0) {
counter.increment();
}
break;
case "decrement":
while (numUpdates-- > 0) {
counter.decrement();
}
break;
default:
return;
}
console.log(`${self.name} is done counting!`);
postMessage({ done: true, count: counter.value });
}
onmessage = handleMessageFromMain;The counter is instantiated here rather than sent as data due to how objects are cloned when passed between threads. Internally, objects are passed to the global structuredClone() method which performs a deep copy (or sometimes transfers the object if used as such) using the structured clone algorithm. This algorithm does not walk the prototype chain, nor does it duplicate getters. So in the case of our Counter object, the methods for updating the counter would not exist.
To quickly try this out, open either a browser console, a Node REPL (by running node in a terminal), or Bun REPL (by running bun repl in a terminal) and enter the following:
class Example {
sayHi() {
console.log("Hi!");
}
}
const original = new Example();
const clone = structuredClone(original);
console.assert(original !== clone);
original.sayHi(); // Hi!
clone.sayHi; // undefined
clone.sayHi(); // Throws `TypeError`As you can see, the original method does not get cloned. Additionally, trying to clone DOM nodes or Function objects will throw, and potential modifications done via property descriptors will not be preserved.
Note that structuredClone() is not a language feature of JavaScript, but most browsers and some JS runtimes (including Node.js, Deno, and Bun) provide it as a Web API.
Triggering Concurrent Writes via UI Interactions
It's time to implement the logic that will be running on the main thread in main.js. We start by allocating 4 bytes of memory for the counter value by creating a SharedArrayBuffer which the workers will eventually use for instantiating a Counter object. When a buffer is created, 0 will internally be written to each byte index of the data block.
Similarly to before, we instantiate four workers via the Worker constructor, then add a listener for handling messages from them. When a message is received signaling that the worker is done counting, we'll go ahead and update the DOM with the current count.
// main.js
if (!Worker) {
console.error("You need to use a browser that supports Web Workers for this example to work.");
}
if (!crossOriginIsolated) {
console.error("The files served need to be cross-origin isolated for this example to work.");
}
const sharedCounterBuffer = new SharedArrayBuffer(Uint32Array.BYTES_PER_ELEMENT);
const NUM_WORKERS = 4;
const workers = initWorkers(NUM_WORKERS);
/**
* Create background threads by initializing workers.
*
* @param {number} size - The number of workers to create.
* @returns {Worker[]} The worker instances.
*/
function initWorkers(size) {
const workers = [];
for (let i = 0; i < size; i++) {
const worker = new Worker("counting-worker.js", {
name: `Worker #${i}`,
type: "module",
});
worker.onmessage = handleMessageFromWorker;
workers.push(worker);
}
return workers;
}
/**
* Handle incoming messages from workers and show the count
* if the worker has signaled that it is done counting.
*
* @param {MessageEvent<{done: boolean, count: number}>} event
*/
function handleMessageFromWorker({ data }) {
if (data.done) {
showCurrentCount(data.count); // <-- We'll define this function soon.
}
}By providing the option { type: "module" } when creating the dedicated worker, the script provided will be loaded as an ES module, making the import statement available in the DedicatedWorkerGlobalScope and enabling strict mode by default (no need to write "use strict;"). The optional name will set the name of the scope the worker is executing in (accessible on self), and is used here solely for printing purposes as we log ${self.name} is done counting! in counting-worker.js.
Next, we'll define functions for triggering the concurrent incrementing and decrementing of the counter (i.e. sending messages to the workers) and set them as the onclick event handlers of our DOM element nodes. As a quick reminder, the index.html file is not shown in full in this blog post, but this is the relevant part:
<body>
<main>
<!-- ... -->
<div>
<p>Counter:</p>
<p id="counter">0</p>
</div>
<div>
<button type="button" id="increment">
+ Trigger concurrent increments
</button>
<button type="button" id="decrement">
- Trigger concurrent decrements
</button>
</div>
</main>
<script type="module" src="main.js"></script>
</body>With that, we grab the element ids and attach our handlers.
// main.js (continuing)
// ...
/**
* Trigger concurrent increments by sending messages
* to the workers with an "increment" instruction.
*/
function triggerConcurrentIncrements() {
for (const worker of workers) {
worker.postMessage({
operation: "increment",
sharedCounterBuffer,
});
}
}
const incrementElement = getElementById("increment");
incrementElement.onclick = triggerConcurrentIncrements;
/**
* Trigger concurrent decrements by sending messages
* to the workers with a "decrement" instruction.
*/
function triggerConcurrentDecrements() {
for (const worker of workers) {
worker.postMessage({
operation: "decrement",
sharedCounterBuffer,
});
}
}
const decrementElement = getElementById("decrement");
decrementElement.onclick = triggerConcurrentDecrements;
const counterElement = getElementById("counter");
/**
* @param {number} count - The count to display.
*/
function showCurrentCount(count) {
counterElement.textContent = count.toLocaleString();
}
/**
* @param {string} id - The element's id.
* @returns {HTMLElement} The element with the given ID.
*/
function getElementById(id) {
const element = document.getElementById(id);
if (element) {
return element;
}
throw new Error(`An element with id '${id}' does not exist.`);
}Our counter implementation using atomics can now be run in the browser. Since SharedArrayBuffer is only supported for cross-origin-isolated pages, see the README of the demo repository to easily serve the files via a local HTTP server.
Clicking on the increment button one time should show:
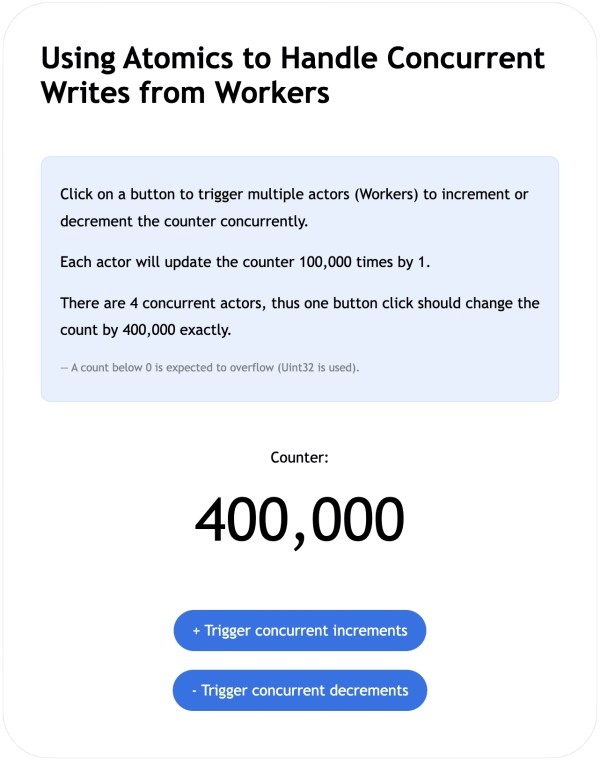
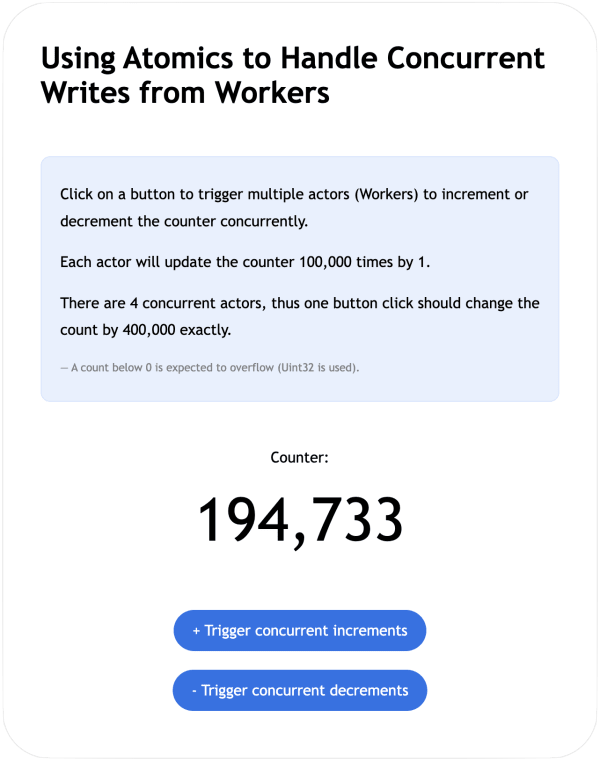
If replacing our counter-example2.js implementation with counter-example1.js (available in the repository) which operates on shared memory without using Atomics, the counter is clearly unpredictable as shown below, resulting from unordered events.
Implementing a Mutex to Create Atomic Operations
So far, Atomics.load(), Atomics.add(), and Atomics.sub() have allowed us to handle concurrent writes in a sequentially consistent way. But as you may have noticed, they only allow for one such atomic instruction at a time. For instance, take a look at the code below.
function updateValue() {
let value = Atomics.load(...);
/* perform calculations.. */
/* modify the `value`.. */
Atomics.store(..., value);
}Between reading the value and storing a new value back into the shared memory, the data may have been modified. If you as the implementer rely on a group of operations to be performed as a transaction, or atomically as seen by another agent, then this cannot be expressed with the aforementioned APIs.
Conceptually, when the function is invoked, we would like the behavior to be something like:
- Tell anyone who tries to access the same data to wait from now on.
- Perform the necessary operations.
- Tell anyone who is waiting that I'm done.
This is often achieved by using a mutually exclusive lock, or mutex; i.e. a lock that can only be owned by one at a time, indicating who has the right to access and modify the shared resource. Using more common terminology for mutexes, the above three steps could be reformulated as:
- Lock access to the shared resource to anyone but me.
- Perform the necessary operations.
- Unlock access.
To handle this, we need mechanisms for waiting if the resource is locked, as well as notifying waiters whenever it is unlocked. This is available on the Atomics object, which gives us the building blocks to create our own Mutex class.
Building upon our counter example, we will add the following:
- A mutex
- Handles locking and unlocking, which internally for the class also means putting agents to sleep by making them wait if necessary, as well as waking them up by notifying them when the resource has been unlocked.
- A counter
- An additional counter implementation which uses the mutex whenever it needs to access the shared buffer.
- Tiny updates
- We will make tiny updates to account for having to provide a buffer for the mutex to use as well.
The Mutex Class
As with our previous counter, the Mutex constructor in our new file mutex.js expects a SharedArrayBuffer since the state of the lock needs to be shared between threads. Momentarily, we will make use of the Atomics.wait() and Atomics.notify() APIs which both require the typed array view to be either an Int32Array or BigInt64Array. Therefore, we instantiate the #bufferView as an Int32Array.
// mutex.js
/**
* A mutually exclusive lock using `Atomics` for coordinating the
* right to access shared memory among multiple agents.
*/
export class Mutex {
/**
* The lock state when access to shared memory is prohibited.
*/
static #LOCKED = 1;
/**
* The lock state when access to shared memory is permitted.
*/
static #UNLOCKED = 0;
/**
* The location in the `bufferView` at which the state is stored.
*/
static #LOCATION = 0;
/**
* The view into the underlying buffer by which it is accessed.
*/
#bufferView;
/**
* Create a mutex backed by shared memory.
*
* @param {SharedArrayBuffer} sharedBuffer - The shared data buffer.
*/
constructor(sharedBuffer) {
this.#ensureSharedArrayBuffer(sharedBuffer);
this.#bufferView = new Int32Array(sharedBuffer);
}
/**
* @param {unknown} value
*/
#ensureSharedArrayBuffer(value) {
if (!(value instanceof SharedArrayBuffer)) {
throw new Error("Expected a 'SharedArrayBuffer'.");
}
const MIN_BYTES = Int32Array.BYTES_PER_ELEMENT;
if (value.byteLength < MIN_BYTES) {
throw new Error(`Expected at least a ${MIN_BYTES}-byte buffer.`);
}
}
}The public methods on this class will be lock() and unlock(). When invoking lock(), it will first try to get the lock by comparing the state (the value stored in the buffer) with Mutex.#UNLOCKED. If it is unlocked, it will exchange that value with Mutex.#LOCKED. This is done atomically via Atomics.compareExchange() which returns the previously stored value. In that case, the lock has successfully been acquired and the execution returns to the caller.
However, if the lock was not acquired (i.e. the previous state was not Mutex.#UNLOCKED), we start another atomic check via Atomics.wait() to see if the state is Mutex.#LOCKED and, if so, the thread will be suspended.
// mutex.js (continuing)
export class Mutex {
// ...
/**
* Try to acquire the lock, or wait until it is released to try again.
*/
lock() {
while (true) {
if (this.#tryGetLock()) {
return;
}
this.#waitIfLocked();
}
}
/**
* Try to acquire the lock by changing the state to `Mutex.#LOCKED`
* if it previously was `Mutex.#UNLOCKED`.
*
* @returns {boolean} Whether the lock was acquired.
*/
#tryGetLock() {
const previousState = Atomics.compareExchange(
this.#bufferView,
Mutex.#LOCATION,
Mutex.#UNLOCKED,
Mutex.#LOCKED,
);
return previousState === Mutex.#UNLOCKED;
}
/**
* If the specified location contains `Mutex.#LOCKED`, put the
* thread to sleep and wait on that location until it is notified.
*
* @note
* This is only supported for an `Int32Array` or `BigInt64Array`
* that views a `SharedArrayBuffer`.
*/
#waitIfLocked() {
Atomics.wait(this.#bufferView, Mutex.#LOCATION, Mutex.#LOCKED);
}
}Take another look at the lock() method above. If this.#waitIfLocked() is reached, it must mean that this.#tryGetLock() returned false due to the state already being Mutex.#LOCKED. But that does not mean that it is still locked by the time Atomics.wait() is called. If it gets unlocked in between, Atomics.wait(.., Mutex.#LOCKED) will return "not-equal" and execution will continue into the next iteration of the loop. Otherwise, if it is still locked, it returns "ok" and goes to sleep.
Now, imagine there are agents that have been put in the wait queue while waiting for the lock to be released. In between the first agent in the queue (potentially the one who has waited the longest) being notified of the state change, and calling this.#tryGetLock() again, another agent might just have called lock(), and thus manages to acquire it before everyone else in the queue. This causes the first agent to go back to sleep and reenter the queue. In that sense, this mutex implementation does not treat agents' requests for the lock fairly.
Atomics.wait() also has a fourth parameter timeout for specifying how many milliseconds to wait until waking up in case it has not yet been notified, at which point it returns "timed-out" and continues execution (the default value is Infinity).
Lastly, since Atomics.wait() is blocking, invoking it on the main thread will throw a TypeError. If the main thread (or workers) needs to wait asynchronously, there is Atomics.waitAsync() which another blog post demonstrates by building an async mutex. At the time of writing, that API is not supported in SpiderMonkey (Firefox).
Knowledge Boost 💪
Several interesting things occur internally when calling Atomics.wait(). Since Atomics.wait() will not only read the value in the buffer, but also potentially do other operations such as adding the agent to a wait queue and suspending the agent, this sequence of events need to be protected from concurrent access. Such a section of a program is referred to as a critical section for that reason, and the protection needed is exactly what the Atomics API should provide for us.
In order to conform to that behavior in this case, ECMAScript uses the notion of Synchronize events-events that will signal whether other events are permitted or not. So prior to reading the value in the buffer (within the internal Atomics.wait() implementation), it tries to enter the critical section. If no one is currently inside that section and no one is waiting to enter it, the agent enters it and creates a new Synchronize event. If the agent has to wait for another one to leave, the section is said to have contention.
Once inside, the value is read from the buffer. If the value does not match the one we passed (Mutex.#LOCKED), it leaves the critical section (including creating a new Synchronize event), then returns. Otherwise, before leaving, the agent is first put in a FIFO (first-in-first-out) wait queue and suspended.
Moving on to implementing unlock().
// mutex.js (continuing)
export class Mutex {
// ...
/**
* Release the lock and notify waiting agents.
*/
unlock() {
if (!this.#tryUnlock()) {
throw new Error("You can only unlock while holding the lock.");
}
this.#notifyAgents();
}
/**
* Try to release the lock by changing the state to `Mutex.#UNLOCKED`
* if it previously was `Mutex.#LOCKED` (which should always be the case
* when this method is called).
*
* @returns {boolean} Whether the lock was released.
*/
#tryUnlock() {
const previousState = Atomics.compareExchange(
this.#bufferView,
Mutex.#LOCATION,
Mutex.#LOCKED,
Mutex.#UNLOCKED,
);
return previousState === Mutex.#LOCKED;
}
/**
* Notify agents waiting on the specified location, which will wake
* them up and allow their execution to continue.
*
* @note
* This is only supported for an `Int32Array` or `BigInt64Array`
* that views a `SharedArrayBuffer`.
*/
#notifyAgents() {
const NUM_AGENTS_TO_NOTIFY = 1;
Atomics.notify(this.#bufferView, Mutex.#LOCATION, NUM_AGENTS_TO_NOTIFY);
}
}When invoking unlock(), it first tries to change the stored value from Mutex.#LOCKED to Mutex.#UNLOCKED via Atomics.compareExchange(). If this does not succeed, the thread was not holding the lock, which should never happen.
Subsequently, agents waiting on Mutex.#LOCATION are notified (in this case, only a maximum of 1 agent is notified). Similarly to what is mentioned in the previous "Knowledge Boost" box, the call to Atomics.notify() will enter the critical section, remove the waiters from the queue, notify the waiters, then leave the critical section. The return value is the number of agents awoken.
The New Counter Class
Let's implement the last counter example in a new file counter-example3.js and import our Mutex class.
Unlike the previous example, this constructor also takes the shared buffer for the mutex. Both the Counter and the Mutex have their #LOCATION fixed to the first element in their respective view, but as mentioned earlier, it is also possible to pass just one buffer along with the offsets, or pass the instantiated Mutex object.
// counter-example3.js
import { Mutex } from "./mutex.js";
/**
* A counter which updates the value in shared memory by using a mutex
* to lock and unlock the right to access that memory. This makes the
* operations appear atomic to other agents, even during concurrent writes.
*/
export class Counter {
/**
* The location in the `bufferView` at which the value is stored.
*/
static #LOCATION = 0;
/**
* The view into the underlying buffer by which it is accessed.
*/
#bufferView;
/**
* The mutex used for acquiring and releasing the lock.
*/
#mutex;
/**
* Create a counter backed by shared memory.
*
* @param {SharedArrayBuffer} sharedCounterBuffer - The shared counter data buffer.
* @param {SharedArrayBuffer} sharedMutexBuffer - The shared mutex data buffer.
*/
constructor(sharedCounterBuffer, sharedMutexBuffer) {
this.#ensureSharedArrayBuffer(sharedCounterBuffer);
this.#bufferView = new Uint32Array(sharedCounterBuffer);
this.#mutex = new Mutex(sharedMutexBuffer);
}
/**
* @param {unknown} value
*/
#ensureSharedArrayBuffer(value) {
if (!(value instanceof SharedArrayBuffer)) {
throw new Error("Expected a 'SharedArrayBuffer'.");
}
const MIN_BYTES = Uint32Array.BYTES_PER_ELEMENT;
if (value.byteLength < MIN_BYTES) {
throw new Error(`Expected at least a ${MIN_BYTES}-byte buffer.`);
}
}
}As seen below, whenever we access the shared memory, we first call this.#mutex.lock(). Until we call this.#mutex.unlock(), we should not expect another agent to access the same memory. Therefore, we can access the #bufferView directly, rather than via the Atomics APIs. Important to note, nonetheless, is that this only holds true if you as the implementer respect these lock conventions.
The mutex is used even for the getter (get value()). This is to prevent reading a half-complete value stored by another agent, which is known as a torn read. Accessing value is thereby blocking in our case. Alternatively, you could make reads non-blocking by always reading the most recent (and potentially old) value stored at a certain memory location, with a guarantee that such a read will eventually be consistent.
// counter-example3.js (continuing)
import { Mutex } from "./mutex.js";
export class Counter {
// ...
/**
* @returns {number} The current count.
*/
get value() {
this.#mutex.lock();
const value = this.#bufferView[Counter.#LOCATION];
this.#mutex.unlock();
return value;
}
/**
* Increment the counter.
*
* @param {number} value - The value to increment by.
*/
increment(value = 1) {
this.#mutex.lock();
this.#bufferView[Counter.#LOCATION] += value;
this.#mutex.unlock();
}
/**
* Decrement the counter.
*
* @param {number} value - The value to decrement by.
*/
decrement(value = 1) {
this.increment(-value);
// NOTE: This is not accounting for decrementing below
// 0, which will overflow due to storing Uint32.
}
}Testing the Counter in the Browser
To hook up our new counter, first import it in counter.js.
// counter.js (updating)
// import { Counter } from "./counter-example1.js";
// import { Counter } from "./counter-example2.js";
import { Counter } from "./counter-example3.js";
export { Counter };In counting-worker.js, pass the data.sharedMutexBuffer when instantiating the counter. We will expect the main thread to send the buffer to this worker. Remember, the main thread does not send the instantiated objects due to how the structured clone algorithm works, as explained earlier.
// counting-worker.js (updating)
import { Counter } from "./counter.js";
/**
* @typedef EventData
* ...
* @property {SharedArrayBuffer} sharedMutexBuffer // <-- Add
*/
/**
* ...
*/
function handleMessageFromMain({ data }) {
const counter = new Counter(
data.sharedCounterBuffer,
data.sharedMutexBuffer, // <-- Add
);
// ...
postMessage({ done: true, count: counter.value });
}The worker still calls postMessage() with the count. But when counter.value is accessed this time, it's a blocking call due to trying to acquire the lock. This is why we are passing the value to the main thread, rather than accessing it on another counter instance in main.js (which would throw an exception).
In main.js, create a new sharedMutexBuffer and add it to the worker.postMessage() calls.
// main.js (updating)
const sharedCounterBuffer = /* same as before */
const sharedMutexBuffer = // <-- Add
new SharedArrayBuffer(Int32Array.BYTES_PER_ELEMENT);
// ...
function triggerConcurrentIncrements() {
for (const worker of workers) {
worker.postMessage({
operation: "increment",
sharedCounterBuffer,
sharedMutexBuffer, // <-- Add
});
}
}
// ...
function triggerConcurrentDecrements() {
for (const worker of workers) {
worker.postMessage({
operation: "decrement",
sharedCounterBuffer,
sharedMutexBuffer, // <-- Add
});
}
}Running this in the browser as before and clicking the button to increment should still produce the expected result:
Thank You for Reading
Concurrency and locks are tricky and there's a ton to learn. But Atomics and shared memory in JavaScript seem like really neat additions to the language, and I hope you've found this time spent valuable.
I greatly enjoyed writing and sharing this blog post with you and learning a lot more about these fairly uncommon APIs in ECMAScript. If you also like digging into and understanding the details more, I encourage you to check out the ECMAScript specification next time you're curious about one of the language features.
Comments powered by Talkyard.
Comments powered byTalkyard.